Contents

A user’s guide
Alejandro R Jadad
4 Assessing the quality of RCTs: why, what, how, and by whom?
- There is no such thing as a perfect trial.
- Internal validity is an essential component of the assessment of trial quality.
- There are many tools to choose from when assessing trial quality, or new ones can be developed.
- Using several people to assess trial quality reduces mistakes and the risk of bias during assessments.
- How to use quality assessment will depend on your role, the purpose of the assessment, and the number of trials on the same topic being evaluated.
- The CONSORT statement aims to improve the standard of written reports of RCTs.
- Answer clear and relevant clinical questions previously unanswered.
- Evaluate all possible interventions for all possible variations of the conditions of interest, in all possible types of patients, in all settings, using all relevant outcome measures.
- Include all available patients.
- Include strategies to eliminate bias during the administration of the interventions, the evaluation of the outcomes, and reporting of the results, thus reflecting the true effect of the interventions.
- Include perfect statistical analyses.
- Be described in reports written in clear and unambiguous language, including an exact account of all the events that occurred during the design and course of the trial, as well as individual patient data, and an accurate description of the patients who were included, excluded, withdrawn, and dropped out.
- Be designed, conducted, and reported by researchers who did not have conflicts of interest.
- Follow strict ethical principles.
Unfortunately, there is no such as thing as a perfect trial. In real life, readers only have imperfect trials to read and face lots of barriers to determining their quality with confidence.
One of the main barriers that hinders the formal assessment of trial quality is that quality is a complex concept or ‘construct’. As with any other construct, such as anxiety, happiness, or love, quality can be acknowledged without difficulty, but it is not easy to define or measure.
Another major barrier is that there is an increasing number of tools available to assess trial quality, but little empirical evidence to guide the selection of tools and the incorporation of assessments into reviews and decisions. There is also little empirical evidence about who should do the assessments (number and background of assessors), about how the assessments should be done (that is, masked vs open conditions), or about the impact of the assessments on health care decisions.
A third major barrier hindering the assessment of trial quality is that, in most cases, the only way to assess quality is by relying on information contained in the written report. The problem is that a trial with a biased design that is well reported could be judged as having high quality, whereas a well designed but poorly reported trial could be judged as having low quality.
In this chapter, I discuss each of these barriers, present the results of recent empirical methodological studies that could help you overcome them, discuss recent efforts to improve the quality of reports of RCTs, and identify areas where further methodological research is required. I hope that the information you find in this chapter will help you not only if you are a clinician trying to decide whether to include an intervention in your armamentarium, but also if you are reading a systematic review and want to evaluate the effect that the assessment of trial quality may have had on the results of the review (see Chapter 7).
Regardless of why you want to assess the quality of a trial or group of trials, the first question that you should try to answer is: What is quality?
Quality means different things to different people. Specific aspects of trials that have been used to define and assess trial quality include the following:1,2
- The clinical relevance of the research question.
- The internal validity of the trial (the degree to which the trial design, conduct, analysis, and presentation have minimised or avoided biased comparisons of the interventions under evaluation).
- The external validity (the precision and extent to which it is possible to generalise the results of the trial to other settings).
- The appropriateness of data analysis and presentation.
- The ethical implications of the intervention they evaluate.
You could define quality by focusing on a single aspect of trials or on a combination of any of the above.1,2 You should, however, take into account that the relevance of the research question, the degree of generalisability of the results, the adequacy of data analysis and presentation, and the ethical implications depend on the context in which they are assessed (that is, they are very much in the eye of the beholder). Of all the aspects of a trial that have been used to define and assess quality, internal validity is the least context-dependent and perhaps the only one that has been the subject of the few empirical methodological studies available. As a result of this, I would recommend that you always include elements related to internal validity in any assessment of the trial quality, complementing them with other aspects of the trial that may be relevant to your specific circumstances. Consider, for example, a trial in which a new antidepressant has been studied in affluent men with suicidal ideation and shown to reduce suicide rates. The generalisability of the results of this trial would be very important if you were a clinician trying to decide whether to offer it to an indigent woman, but would be irrelevant if you were a peer-reviewer trying to decide whether to recommend the report for publication. The internal validity of the trial would, however, be important in both cases. Internal validity is an important and necessary component of the assessment of trial quality, but it is not sufficient to provide a comprehensive evaluation of a trial.
What type of tools can be used to assess trial quality?
Once you establish what quality means to you, the next step is to select a tool to generate the assessments. At this point you can develop your own tool or you can use an existing one.
What is involved in developing a new tool to assess trial quality?
If you decide to develop your own tool, you can create the tool by selecting a single item or a group of items that you (and perhaps a group of colleagues) regard as important according to your definition of quality, decide how to score each item, and use the tool straight away. For example, after deciding to focus on internal and external validity, you could select ‘concealment of allocation’ as the only item for judging internal validity, and ‘definition of inclusion and exclusion criteria’ and ‘description of the primary outcome’ as markers of external validity. After selecting the items, you can decide, on your own or after discussion with your colleagues, to assign two points to a trial with adequate concealment and one point each for adequate descriptions of inclusion/exclusion criteria and the primary outcome. Once you have the items and the scoring system, you can just apply them to trials and obtain scores that would reflect their quality. The advantage of this approach is that it is relatively simple and always yields an assessment tool. The disadvantage is that tools created using this informal approach can produce variable assessments of the same trials when used by multiple individuals, and may not be able to discriminate between studies with good and poor quality.
Alternatively, you could develop the new tool following established methodological procedures similar to those used in the formal development of any other type of health measurement tool. The advantages of this approach are that it is systematic, it can be replicated by others (if properly described), and it can yield tools with known reliability and construct validity which would allow readers to discriminate among trials of varied quality. A description of these procedures is beyond the scope of this book, but can be found elsewhere.3 The following is, however, a list of the steps for developing a new tool to assess trial quality:
- Definition of the construct ‘quality’ (as described in the previous section).
- Definition of the scope of the tool: for instance, the tool could be condition specific (that is, assess only the quality of trials in obstetrics) or intervention specific (that is, assess trials evaluating different types of episiotomies).
- Definition of the population of end users: the tool could be designed for use by clinicians, statisticians or patients, or by individuals with any background.
- Selection of candidate items to include in the tool: usually, this is achieved by asking a group of individuals to propose items to include in the tool, selecting them from items in existing tools, or using their own judgment and expertise.
- Development of a prototype tool: this is usually achieved by getting the individuals who proposed items to meet and decide, by consensus, on the essential group of items that should be included in the tool. At this point, the group can also decide on the wording of each item and on a scoring system. The prototype could be tested by using it to score a small group of trials and, using the experience gathered during the process, to refine the wording and modify the order in which the items are presented.
- Selection of targets: once a prototype tool has been developed, the developers should select a group of trials to be assessed using the tool. These trials have different judged degrees of quality (that is, some should be regarded as having poor quality, whereas others should be regarded as having high quality).
- Selection of raters: the developers should select a group of individuals to use the tool to score the target trials. The characteristics of these individuals should reflect the potential users of the tool.
- Assessment of the trials: the trials are given to the raters to assess, with or without previous training on the use of the tool.
- Evaluation of the consistency of the assessments: this involves measurement of the degree to which different raters agree on the quality of the trials. This is called interobserver or interrater reliability. Reliability is also referred to as consistency or agreement. Rarely, this also includes an evaluation of the degree of intraobserver or intrarater reliability, or the degree of agreement between quality assessments done by the same raters on separate occasions. There are several methods to measure the consistency of the measurements (for example, percentage agreement, k, correlation coefficient, intraclass correlation coefficient). A description of these methods and their advantages and limitations is described elsewhere.3
- Evaluation of ‘construct’ validity: in this case, validity refers to the ability of the tool to measure what it is believed to be measuring. One important limitation to the evaluation of the construct validity of a tool for assessing trial quality is the lack of a gold standard. To overcome this limitation, the developers usually have to make predictions on how the tool would rate trials previously judged as having different quality and testing these predictions. In this case, you would expect the tool to differentiate between the trials previously judged as having poor quality and those judged as having good quality.
- Proposal of a refined tool: once the tool is shown to be reliable and valid, it is ready for use.
The main disadvantage of developing a new tool is that it is a time-consuming process. To avoid developing a new tool using the established methodology or creating one without proper evaluation, the reader can choose to select an existing tool
How many tools exist to evaluate trial quality?
Existing tools to assess trial quality can be classified broadly into those that include individual components and those that include groups of components.
A component represents an item that describes a single aspect of quality. Assessing trial quality using a component can be achieved by scoring the component as present or absent or by judging the adequacy of the information available on the component. For example, concealment of patient assignment could be judged as present or absent or, if it could be judged as adequate, unclear or inadequate.4 There are empirical methodological studies suggesting a relationship between at least five specific components and the likelihood of bias in trials. Most of these studies are described in Chapter 3. Briefly, these studies suggest that trials with inadequate randomisation or double-blinding, inadequate or unclear concealment of allocation, or inappropriately used crossover designs are more likely to produce larger treatment effects than those obtained by their counterparts.4-7 There is also evidence suggesting that reports of trials sponsored by pharmaceutical companies are more likely to favour the experimental intervention over controls than trials not sponsored by pharmaceutical companies.8 Even though individual components are quick and easy to score, using a single component to assess quality is not recommended because it provides minimal information about the overall quality of trials.2
The narrow view provided by individual components can be overcome by using several components grouped in checklists or scales. The main difference between a checklist and a scale is that, in a checklist, the components are evaluated separately and do not have numerical scores attached to them, whereas, in a scale, each item is scored numerically and an overall quality score is generated.2 A systematic search of the literature identified nine checklists and 25 scales for assessing trial quality.9 Ongoing efforts to update this literature search suggest that there are now at least twice as many scales for assessing trial quality and that their number is likely to keep increasing.10 Among the available checklists and scales, only one has been developed using established methodological procedures.1
What are the characteristics of the validated tool to assess trial quality?
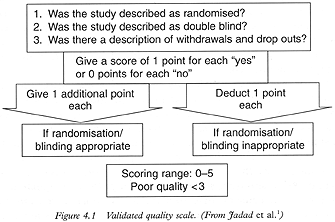
The validated tool is a scale (Fig 4.1) that I developed using the steps outlined in the previous sections as part of a doctoral work on pain relief.11 Since its development, the scale has been used by other investigators who have confirmed that it is easy and quick to use (it takes less than five minutes to score a trial report), provides consistent measurements (even those provided by consumers with no health care background), and has construct validity.1,9,12-14 The scale has been used successfully to identify systematic differences among trials in the areas of infertility,7 homoeopathy,15 anaesthesia,14 pain relief,16 and neonatology,12 as well as in sets of trials published in five different languages.17,18
The scale includes three items that are directly related to bias reduction and are presented as questions to elicit ‘yes’ or ‘no’ answers. The scale produces scores from 0 to 5. Point awards for the first two items (randomisation and double-blinding) depend not only on whether the trial is described as randomised or double-blind, but also on the appropriateness of the methods used to randomise and blind the trial. For example, if the trial is described as randomised or double-blind, but there is no description of the methods used to generate the randomisation sequence or the double-blind conditions, 1 point is awarded in each case (that is, 1 point is awarded for randomisation and 1 point for double-blinding if the trial is described as both randomised and double-blind, or only 1 point is awarded if the trial is described as randomised but not as double-blind). If the methods of generating the randomisation sequence or creating blinded conditions are described and are appropriate, 1 additional point is given for each item (see Chapter 3). Conversely, if the methods used to generate the randomisation sequence or create blinded conditions are described, but inappropriate, the relevant item is given 0 points. The third item of the scale, withdrawals and drop outs, is awarded 0 points for a negative answer and 1 point for a positive answer. For a positive answer, the number of withdrawals and drop outs in each group and the reasons must be stated in the report. If there were no withdrawals, this should also be stated (Fig 4.1). If a trial provides the number and reasons for withdrawals and drop outs in each group, you, as a reader, could reanalyse the data. At the time of the development of the scale, it was debated whether this item should be scored according to the proportion of withdrawals and drop outs in the trials, but this was considered inappropriate because we do not know precisely when a trial has too many drop outs. Once you have scored all the items of the scale, a trial could be judged as having poor quality if it is awarded 2 points or less. It has been shown that studies that obtain 2 or less points are likely to produce treatment effects which are 35% larger than those produced by trials with 3 or more points.19
You can use the overall score produced by the scale or use individual items. The use of the individual items is the most appropriate option if you do not feel comfortable with lumping different aspects of a trial into a single score or when the reports describe trials in areas where double-blinding is not feasible or appropriate (that is, surgical trials). Even trials that cannot be double-blind can, however, still be awarded more than 2 points if they were conducted and reported properly, and thus leave the category of poor trials. Trials could be awarded 3 points if they included a description of appropriate methods to generate the randomisation sequence (2 points) and a detailed account of withdrawals and drop outs (1 point).
This scale by no means represents the only or most appropriate way to assess trial quality, but it is the only validated tool available and appears to produce robust and valid results in an increasing number of empirical methodological studies. This does not mean that the scale should be used in isolation. Instead, you should complement it with separate assessments of any components for which there is empirical evidence of a direct relationship with bias. In addition, you could also add separate assessments of any other component or group of components related to other aspects of trial quality (for example, external validity, quality of data analysis, or presentation, and so on) that you think are important in each case. My current practice, for instance, includes the use of the validated scale together with a separate assessment of concealment of allocation, sources of funding, language of publication, country of publication, and, when applicable, the appropriateness of crossover design.
Who should do the assessments and how?
For more than 10 years it has been suggested that the quality of trial reports should be assessed under masked conditions, that is, without the knowledge of the authors, institutions, sponsorship, publication year and journal, or study results.5 There are, however, only two published empirical studies addressing this issue.1,20 One of these studies showed that assessments under masked conditions were more likely to yield lower and more consistent scores than assessments under open conditions.1 The other study also showed that lower scores were obtained under masked conditions.20 These results imply that bias could be introduced by assessments under open conditions. There is evidence, however, suggesting that the differences in the scores obtained under open or masked conditions may not be important.20 Masking the reports would reduce the likelihood of bias marginally, but it would also increase the resources required to conduct the assessments. Given the methodological and financial implications of these findings, and the small amount of empirical evidence available, I would not recommend that you mask the trial reports as a mandatory step during the assessment of their quality.
Another issue that you should take into account is the number and background of the people required to assess the quality of a given trial. Again, if you are a clinician trying to keep up to date, this is not an issue, because you will be the only person assessing the quality of a particular trial at a given point in time. If, however, you are reading a systematic review done by others, you may want to see if the authors provide information on who assessed trial quality. Typically, systematic reviewers ask two individuals (called raters, observers, or assessors) to assess the trials independently. They are given copies of the trial reports, the assessment instrument(s) with instructions, and a form on which to complete the assessments. The purpose of using multiple individuals to assess trial quality is to minimise the number of mistakes (usually caused by oversight while reading the trial report), and the risk of bias during the assessments. Once they have completed the assessments, the raters are invited to meet to discuss their findings and agree on a single quality assessment for each trial. Reaching agreement on trial quality is usually easy, but on occasions it may require a third person to act as arbiter. The degree of agreement between the raters can be quantified using methods previously described (that is, percentage agreement, k, correlation coefficient, intraclass correlation coefficient). These methods and their advantages and limitations have been described elsewhere.3 If the raters reach consensus, however, the value of measuring interrater agreement is limited.
How can the quality assessments be used?
Once you have assessed the quality of one or more trials, you should use the assessments to guide your decisions. How you use the assessments, however, will depend on your role, the purpose of the quality assessments, and the number of trials on the same topic that you are evaluating. For example:
- If you are a clinician, you may want to use the assessments to judge whether the results of a trial are credible and applicable to your own patients.
- If you are a peer-reviewer or a journal editor, you may want to use the assessments to decide whether a report should be published.
- If you are a researcher planning a new trial, you may want to use the assessments of similar existing trials to decide whether the new trial is justified or, if justified, to improve its design.
- If you are a reviewer, you may want to use the quality assessments to decide how much each trial should influence the overall analysis of all the evidence available on a particular topic.
There are different approaches to incorporate quality assessments into your decisions. If you are a clinician, a peer-reviewer, or a journal editor, and you are dealing with only one trial, you could set thresholds below which the trial would have limited value to guide your clinical decisions or to be published. For instance, if you are a clinician evaluating a trial in which the main outcomes are subjective, you may decide to use the trial to guide your decisions only if it is double-blind and the authors provide a detailed account of co-interventions. In addition, as a journal editor you may decide not to publish trials in which allocation was not concealed and that do not provide a detailed account of the flow of participants.
The situation is more complicated if you are reading or conducting a review of multiple trials on the same topic. In this case, there are several approaches that could be used to incorporate quality assessments,2,7,21 but little research evidence has evaluated the impact of any of these methods on the results of the reviews.2 These approaches include the following.
Tabulation of the quality assessments
The only purpose of this approach is to inform the readers of the review about the quality of the evidence provided by the available trials and to let them judge the credibility of such evidence. A variation of this approach is to display the results of each trial in a figure, sorting them in descending order according to their quality.
Use of quality assessments as thresholds to include or exclude trials from a review
This approach is used frequently, but can produce widely variable results, depending on the instrument and the threshold used.22
Use of quality assessments to conduct sensitivity analyses
This approach is used (see Chapter 6) to assess the robustness of the conclusions of a systematic review. It includes several steps: first, the quality of all trials included in the review is assessed; second, all trials are grouped according to their quality (that is, one group with trials of low quality and another with trials of high quality); third, the evidence provided by the trials within each group is synthesised; fourth, the evidence provided by all trials, regardless of their quality, is synthesised; fifth, the results of the evidence synthesis is compared across the groups (the results obtained from trials of low quality are compared with the results produced by trials with high quality, and both are compared with the results of the synthesis of the evidence from all trials). If the results are similar across the groups, you could conclude that the effects of the intervention are robust and you should feel confident with the conclusions that you draw. If the results are different, you will have to seek possible reasons and be cautious about the conclusions that you draw from the available evidence. For example, a sensitivity analysis of nine trials on antioestrogens for the treatment of male infertility showed that low quality studies produced a positive effect with treatment, whereas no benefit was observed with high quality trials. The overall synthesis of all trials suggested a marginal improvement in pregnancy rate (in the spouses, of course) with antioestrogen treatment.7 These discrepant results helped authors conclude that poor studies were exaggerating the overall estimate of treatment effect and that decisions ignoring the results from studies of high quality could lead to more harm than good. This may be the most appropriate approach to incorporate quality assessments in reviews, given that it does not exclude information, allows the reviewer to assess the robustness of the conclusions, and allows the reader to replicate the analyses if necessary.
Use of quality assessments as the input sequence for cumulative meta-analysis
Meta-analysis refers to the statistical combination of the results of independent studies included in a review with the purpose of producing a quantitative estimate of the overall effect of the interventions under evaluation (see Chapter 6). Typically, data from all relevant trials are combined at once. The reviewers, however, may decide to use a technique called cumulative meta-analysis, which combines the trials sequentially. The quality of the trials could be used as the criterion to decide the order in which the trials are selected for combination. For instance, the first meta-analysis would include the combination of the results from the two trials with the highest quality; the second meta-analysis would include the results of the first three trials with the highest quality; and so on. The purpose of this approach is to allow the reviewer to determine the effect of trial quality on overall estimates of effect. Although attractive, little is known about the value of this approach.
Use of quality assessments to ‘weight’ trials included in meta-analyses
This is perhaps the most aggressive method to incorporate quality assessments in reviews. It requires the incorporation of the actual quality assessments into the conventional formulae used to conduct meta-analysis. The purpose of this approach is to allow trials of high quality to influence the overall effect estimate more than trials with low quality. This is the least studied approach and the most likely to provide estimates that will vary according to the method used to report the quality assessments.
Recent efforts to improve the quality of reporting of RCTs
By this point I hope that you will be convinced that a major barrier hindering the assessment of trial quality is that, in most cases, we must rely on the information contained in the written report. The problem is that a trial with a biased design that is well reported could be judged as having high quality, whereas a well designed but poorly reported trial could be judged as having low quality. If you contact the authors of the report directly, they may be able to provide the missing information that you require to complete the quality assessments, but they may not have such information available or they may give you false information (that is, it would be easy for them to tell you that a trial that they published 20 years ago included concealment of allocation). Ideally, all these problems could be avoided if the authors of trial reports provided enough information for the readers to judge whether the results of the trials are reliable.
In 1996, a group of clinical epidemiologists, biostatisticians, and journal editors published a statement called CONSORT (Consolidation of the Standards of Reporting Trials), which resulted from an extensive collaborative process with the aim of improving the standard of written reports of RCTs.22 The CONSORT statement was designed to assist the reporting of RCTs with two groups and those with parallel designs. Some modifications will be required to report crossover trials and those with more than two groups.23
The CONSORT statement includes a checklist of 21 items and a flow diagram for use by the authors to provide journal editors and peer-reviewers with the page of the report in which each of the 21 items is addressed. The flow chart provides a detailed description of the progress of participants through the randomised trial, from the number of potentially eligible individuals for inclusion in the trial to the number of trial participants in each group who completed the trial.23 Each of the items in the checklist and the elements of the flow chart are described in detail in Chapter 5.
Will the quality of RCTs improve?
Soon after its publication, the CONSORT statement was endorsed by major journals such as the British Medical Journal, The Lancet, the Journal of the American Medical Association, and the Canadian Medical Association Journal. These journals incorporated the CONSORT statement as part of the requirements for authors from 1 January 1997. Within six months of the publication of the statement, another 30 journals endorsed it.
Although the CONSORT statement was not evaluated before its publication, it is expected that it will lead to an improvement in the quality of reporting of RCTs, at least in the journals that have endorsed it. It is also expected that the actual quality of the trials will improve as a result of authors being aware of the requirements for submission of trial reports.The overall effect of CONSORT and other initiatives to improve the quality of RCTs is hard to predict, taking into account that there are more than 30 000 biomedical journals and that their number is likely to continue increasing exponentially.25 Whether there is a substantial improvement in the overall quality of future trials will depend on the extent to which researchers and editors agree that there is a need to improve their quality and are willing to make the necessary efforts to improve it.
References
Jadad AR, Moore RA, Carroll D, Jenkinson C, Reynolds JM, Gavaghan DJ, McQuay DM. Assessing the quality of reports on randomized clinical trials: Is blinding necessary? Controlled Clin Trials 1996;17:1-12.
Moher D, Jadad AR, Tugwell P. Assessing the quality of randomized controlled trials. Int J Technol Assess Health Care 1996;12:195-208.
Streiner DL, Norman GR. Health measurement scales: a practical guide to their development and use, 2nd edn. Oxford: Oxford University Press, 1996.
Schulz KF, Chalmers I, Hayes RJ, Altman DG. Empirical evidence of bias: dimensions of methodological quality associated with estimates of treatment effect in controlled clinical trials. JAMA 1995;273:408-12.
Chalmers TC, Celano P, Sacks HS, Smith H. Bias in treatment assignment in controlled clinical trials. N Engl J Med 1983;309:1359-61.
Colditz GA, Miller JN, Mosteller F. How study design affects outcomes in comparisons of therapy. I. Therapy. Stat Med 1989;8:441-54.
Khan KS, Daya S, Jadad AR. The importance of quality of primary studies in producing unbiased systematic reviews. Arch Intern Med 1996;156:661-6.
Cho MK, Bero LA. The quality of drug studies published in symposium proceedings. Ann Intern Med 1996;124:485-9.
Moher D, Jadad AR, Nichol G, Penman M, Tugwell P, Walsh S. Assessing the quality of randomized controlled trials: an annotated bibliography of scales and checklists. Controlled Clin Trials 1995;16:62-73.
Jadad AR, Cook DJ, Jones AL, Klassen TP, Tugwell P, Moher M, Moher D. The quality of randomised controlled trials included in meta-analyses and systematic reviews: how often and how is it assessed? Published as: Abstract presented at the 4th Cochrane Colloquium, Adelaide, Australia, October, 1996. In Review at Br Med J.
Jadad AR. Meta-analysis of randomised clinical trials in pain relief. DPhil thesis, University of Oxford, 1994.
Ohlsson A, Lacy JB. Quality assessments of randomized controlled trials: evaluation by the Chalmers versus the Jadad method. 3rd Annual Cochrane Colloquium 1995:V9-V10.
Egger M, Zellweger T, Antes G. Randomized trials in German-language journals. Lancet 1996;347:1047-8.
Bender JS, Halpern SH, Thangaroopan M, Jadad AR, Ohlsson A. Quality and retrieval of obstetrical anaesthesia randomized controlled trials. Can J Anaesth 1997;44:14-18.
Linde K, Clausius N, Ramirez G, Melchart D, Eitel F, Hedges LV, Jonas WB. Are the clinical effects of homeopathy placebo effects? A meta-analysis of placebo-controlled trials. Lancet 1997;350:834-43.
McQuay H, Carroll D, Jadad AR, Wiffen P, Moore A. Anticonvulsant drugs for management of pain: a systematic review. BMJ 1995;311:1047-52.
Moher D, Fortin P, Jadad AR, Juni P, Klassen T, LeLorier J, Liberati A, Linde K, Penna A. Completeness of reporting of trials published in languages other than English: implications for conduct and reporting of systematic reviews. Lancet 1996;347:363-6.
Egger M, Zellweger-Zahner T, Schneider M, Junker C, Lengeler C, Antes G. Language bias in randomised controlled trials published in English and German. Lancet 1997;350:326-9.
Moher D, Jones A, Cook DJ, Jadad AR, Moher M, Tugwell P, Klassen TP. Does the poor quality of reports of randomized trials exaggerate estimates of intervention effectiveness reported in meta-analysis? In Press. Lancet.
Berlin JA for the University of Pennsylvania Meta-analysis Blinding Study Group. Does blinding of readers affect the results of meta-analyses? Lancet 1997;350:185-6.
Detsky AS, Naylor CD, O'Rourke K, McGeer AJ, L'Abbe KA. Incorporating variations in the quality of individual randomized trials into meta-analysis. J Clin Epidemiol 1992;45:255-65.
Begg C, Cho M, Eastwood S, Horton R, Moher D, Olkin I, Pitkin R, Rennie D, Schulz KF, Simel D, Stroup D. Improving the quality of reporting of randomized controlled trialsThe CONSORT Statement. JAMA 1996;276:7-9.
Altman DG. Better reporting of randomised controlled trials: the CONSORT statement. BMJ 1996;313:570-1.
Smith R. Where is the wisdom? BMJ 1991;303:798-9.
|

Home | Contents | Foreword | Introduction | Acknowledgments | How to order
© BMJ Books 1998. BMJ Books is an imprint of the BMJ Publishing Group. First published in 1998 by BMJ Books, BMA House, Tavistock Square, London WC1H 9JR. A catalogue record for this book is available from the British Library. ISBN 0-7279-1208-9
![]()